and at least one inequality is strict. If all inequalities are strict, then the matrix is said to be has strict diagonal dominance.
Diagonally dominant matrices arise quite often in applications. Their main advantage is that iterative methods for solving SLAEs with such a matrix (simple iteration method, Seidel method) converge to an exact solution that exists uniquely for any right-hand side.
Properties
- A matrix with strict diagonal dominance is non-singular.
see also
Write a review about the article "Diagonal dominance"
Excerpt characterizing Diagonal Predominance
The Pavlograd Hussar Regiment was stationed two miles from Braunau. The squadron, in which Nikolai Rostov served as a cadet, was located in the German village of Salzenek. The squadron commander, captain Denisov, known throughout the cavalry division under the name Vaska Denisov, was allocated the best apartment in the village. Junker Rostov, ever since he caught up with the regiment in Poland, lived with the squadron commander.On October 11, the very day when everything in the main apartment was raised to its feet by the news of Mack's defeat, at the squadron headquarters, camp life calmly went on as before. Denisov, who had lost all night at cards, had not yet come home when Rostov returned from foraging early in the morning on horseback. Rostov, in a cadet's uniform, rode up to the porch, pushed his horse, threw off his leg with a flexible, youthful gesture, stood on the stirrup, as if not wanting to part with the horse, finally jumped off and shouted to the messenger.
NON-SENERACY OF MATRICES AND THE PROPERTY OF DIAGONAL DOMINANCE1
© 2013 L. Cvetkovic, V. Kostic, L.A. Crookier
Liliana Cvetkovic - Professor, Department of Mathematics and Computer Science, Faculty of Science, University of Novi Sad, Serbia, Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [email protected].
Kostic Vladimir - assistant professor, doctor, Department of Mathematics and Informatics, Faculty of Science, University of Novi Sad, Serbia, Obradovica 4, 21000, Novi Sad, Serbia, email: [email protected].
Krukier Lev Abramovich - Doctor of Physical and Mathematical Sciences, Professor, Head of the Department of High-Performance Computing and Information and Communication Technologies, Director of the South Russian Regional Center for Informatization of the Southern Federal University, Stachki Ave. 200/1, bldg. 2, Rostov-on-Don, 344090, e-mail: krukier@sfedu. ru.
Cvetkovic Ljiljana - Professor, Department of Mathematics and Informatics, Faculty of Science, University of Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [email protected].
Kostic Vladimir - Assistant Professor, Department of Mathematics and Informatics, Faculty of Science, University of Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, e-mail: [email protected].
Krukier Lev Abramovich - Doctor of Physical and Mathematical Science, Professor, Head of the Department of High Performance Computing and Information and Communication Technologies, Director of the Computer Center of the Southern Federal University, Stachki Ave, 200/1, bild. 2, Rostov-on-Don, Russia, 344090, e-mail: krukier@sfedu. ru.
Diagonal dominance in a matrix is a simple condition ensuring its non-degeneracy. Properties of matrices that generalize the concept of diagonal dominance are always in great demand. They are considered as conditions of the diagonal dominance type and help to define subclasses of matrices (such as H-matrices) that remain non-degenerate under these conditions. In this work, new classes of non-singular matrices are constructed that retain the advantages of diagonal dominance, but remain outside the class of H-matrices. These properties are especially convenient since many applications lead to matrices from this class, and the theory of nondegeneracy of matrices that are not H-matrices can now be extended.
Keywords: diagonal dominance, non-degeneracy, scaling.
While simple conditions that ensure nonsingularity of matrices are always very welcomed, many of which can be considered as a type of diagonal dominance tends to produce subclasses of a well known H-matrices. In this paper we construct a new classes of nonsingular matrices which keep the usefulness of diagonal dominance, but stand in a general relationship with the class of H-matrices. This property is especially favorable, since many applications that arise from H-matrix theory can now be extended.
Keywords: diagonal dominance, nonsingularity, scaling technique.
The numerical solution of boundary value problems of mathematical physics, as a rule, reduces the original problem to solving a system of linear algebraic equations. When choosing a solution algorithm, we need to know whether the original matrix is non-singular? In addition, the question of the non-degeneracy of a matrix is relevant, for example, in the theory of convergence of iterative methods, localization of eigenvalues, when estimating determinants, Perron roots, spectral radius, singular values of the matrix, etc.
Note that one of the simplest, but extremely useful conditions ensuring the non-degeneracy of a matrix is the well-known property of strict diagonal dominance (and references therein).
Theorem 1. Let a matrix A = e Cnxn be given such that
s > g (a):= S k l, (1)
for all i e N:= (1,2,...n).
Then matrix A is non-degenerate.
Matrices with property (1) are called matrices with strict diagonal dominance
(8BB matrices). Their natural generalization is the class of generalized diagonal dominance (vBD) matrices, defined as follows:
Definition 1. A matrix A = [a^ ] e Cxn is called an BB-matrix if there exists a non-singular diagonal matrix W such that AW is an 8BB-matrix.
Let us introduce several definitions for the matrix
A = [au] e Sphp.
Definition 2. Matrix (A) = [tuk], defined
(A) = e Cn
is called the comparison matrix of matrix A.
Definition 3. Matrix A = e C
\üj > 0, i = j
is an M-matrix if
aj< 0, i * j,
reverse mat-
ritsa A" >0, i.e. all its elements are positive.
It is obvious that matrices from the vBB class are also non-singular matrices and can be
1This work was partially supported by the Ministry of Education and Science of Serbia, grant 174019, and the Ministry of Science and Technological Development of Vojvodina, grants 2675 and 01850.
found in the literature under the name of non-degenerate H-matrices. They can be determined using the following necessary and sufficient condition:
Theorem 2. The matrix A = [ау]е сых is Н-
matrix if and only if its comparison matrix is a non-singular M-matrix.
By now, many subclasses of non-singular H-matrices have already been studied, but all of them are considered from the point of view of generalizations of the property of strictly diagonal dominance (see also the references therein).
This paper considers the possibility of going beyond the class of H-matrices by generalizing the 8BB class in a different way. The basic idea is to continue using the scaling approach, but with matrices that are not diagonal.
Consider the matrix A = [ау] e спхн and the index
Let's introduce the matrix
r (A):= £ a R (A):= £
ßk (A) := £ and yk (A) := aü - ^
It is easy to check that the elements of the matrix bk abk have the following form:
ßk (A), У k (A), akj,
i = j = k, i = j * k,
i = k, j * k, i * k, j = k,
A inöaeüiüö neö^äyö.
If we apply Theorem 1 to the matrix bk ABk1 described above and its transpose, we obtain two main theorems.
Theorem 3. Let any matrix be given
A = [ау] e схп with non-zero diagonal elements. If there exists k e N such that > Tk(A), and for each g e N\(k),
then matrix A is non-singular.
Theorem 4. Let any matrix be given
A = [ау] e схп with non-zero diagonal elements. If there exists k e N such that > Jak(A), and for each r e N\(k),
Then matrix A is non-degenerate. A natural question arises about the connection between
matrices from the previous two theorems: b^ - BOO -matrices (defined by formula (5)) and
Lk - BOO -matrices (defined by formula (6)) and the class of H-matrices. The following simple example makes this clear.
Example. Consider the following 4 matrices:
and consider the matrix bk Abk, k e N, similar to the original A. Let us find the conditions when this matrix will have the property of an SDD matrix (in rows or columns).
Throughout the article we will use the notation for r,k eN:= (1,2,.../?)
2 2 1 1 3 -1 1 1 1
" 2 11 -1 2 1 1 2 3
2 1 1 1 2 -1 1 1 5
Nondegeneracy theorems
All of them are non-degenerate:
A1 is b - BOO, despite the fact that it is not bk - BOO for any k = (1,2,3). It is also not an H-matrix, since (A^ 1 is not non-negative;
A2, due to symmetry, is simultaneously bA - BOO and b<2 - БОО, так же как ЬЯ - БОО и
b<3 - БОО, но не является Н-матрицей, так как (А2) вырожденная;
A3 is b9 - BOO, but is neither
Lr - SDD (for k = (1,2,3)), nor an H-matrix, since (A3 ^ is also singular;
A4 is an H-matrix since (A^ is non-singular, and ^A4) 1 > 0, although it is neither LR - SDD nor Lk - SDD for any k = (1,2,3).
The figure shows the general relationship between
Lr - SDD, Lk - SDD and H-matrices along with the matrices from the previous example.
Relationship between lR - SDD, lC - SDD and
ad min(|au - r (A)|) "
Starting with inequality
and applying this result to the matrix bk AB^, we obtain
Theorem 5. Let an arbitrary matrix A = [a-- ] e Cxn be given with non-zero diagonal elements
cops. If A belongs to the class - BOO, then
1 + max^ i*k \acc\
H-matrices
It is interesting to note that although we received
class of LKk BOO -matrices by applying Theorem 1 to the matrix obtained by transposing the matrix Lk AB^1, this class does not coincide with the class obtained by applying Theorem 2 to the matrix At.
Let's introduce some definitions.
Definition 4. Matrix A is called ( Lk -BOO by rows) if AT ( Lk - BOO ).
Definition 5. Matrix A is called ( bSk -BOO by rows) if AT ( bSk - BOO ).
Examples show that classes Shch - BOO,
BC-BOO, ( bk - BOO by lines) and ( b^-BOO by lines) are connected with each other. Thus, we have extended the class of H-matrices in four different ways.
Application of new theorems
Let us illustrate the usefulness of the new results in estimating the C-norm of an inverse matrix.
For an arbitrary matrix A with strict diagonal dominance, the well-known Varach theorem (VaraI) gives the estimate
min[|pf (A)| - tk (A), min(|yk (A)| - qk(A) - |af (A)|)]" i i (фf ii ii
Similarly, we obtain the following result for the Lk - SDD matrices by columns.
Theorem 6. Let an arbitrary matrix A = e cihi with nonzero diagonal elements be given. If A belongs to class bk -SDD by columns, then
Ik-lll<_ie#|akk|_
" " mln[|pf (A)| - Rf (AT), mln(|уk (A)|- qk (AT)- |aft |)]"
The importance of this result is that for many subclasses of non-singular H-matrices there are restrictions of this type, but for those non-singular matrices that are not H-matrices this is a non-trivial problem. Consequently, restrictions of this kind, as in the previous theorem, are very popular.
Literature
Levy L. Sur le possibilité du l "equlibre electrique C. R. Acad. Paris, 1881. Vol. 93. P. 706-708.
Horn R.A., Johnson C.R. Matrix Analysis. Cambridge, 1994. Varga R.S. Gersgorin and His Circles // Springer Series in Computational Mathematics. 2004. Vol. 36.226 rub. Berman A., Plemons R.J. Nonnegative Matrices in the Mathematical Sciences. SIAM Series Classics in Applied Mathematics. 1994. Vol. 9. 340 rub.
Cvetkovic Lj. H-matrix theory vs. eigenvalue localization // Numer. Algor. 2006. Vol. 42. P. 229-245. Cvetkovic Lj., Kostic V., Kovacevic M., Szulc T. Further results on H-matrices and their Schur complements // Appl. Math. Comput. 1982. P. 506-510.
Varah J.M. A lower bound for the smallest value of a matrix // Linear Algebra Appl. 1975. Vol. 11. P. 3-5.
Received by the editor
Definition.
Let us call a system a system with diagonal row dominance if the matrix elementssatisfy the inequalities:
 ,
,

Inequalities mean that in each row of the matrix  the diagonal element is highlighted: its modulus is greater than the sum of the moduli of all other elements of the same row.
the diagonal element is highlighted: its modulus is greater than the sum of the moduli of all other elements of the same row.
Theorem
A system with diagonal dominance is always solvable and, moreover, in a unique way.
Consider the corresponding homogeneous system:
 ,
,

Let's assume that it has a nontrivial solution  , Let the largest modulo component of this solution correspond to the index
, Let the largest modulo component of this solution correspond to the index  , i.e.
, i.e.
 ,
, ,
,
 .
.
Let's write it down  th equation of the system in the form
th equation of the system in the form

and take the modulus of both sides of this equality. As a result we get:
 .
.
Reducing inequality by a factor  , which, according to us, is not equal to zero, we come to a contradiction with the inequality expressing diagonal dominance. The resulting contradiction allows us to consistently make three statements:
, which, according to us, is not equal to zero, we come to a contradiction with the inequality expressing diagonal dominance. The resulting contradiction allows us to consistently make three statements:

The last of these means that the proof of the theorem is complete.
Systems with a tridiagonal matrix. Running method.
When solving many problems, one has to deal with systems of linear equations of the form:
, ,
,
 ,
, ,
,
where are the coefficients  , right sides
, right sides 
 known along with the numbers
known along with the numbers  And
And  . Additional relations are often called boundary conditions for the system. In many cases they can be more complex. For example:
. Additional relations are often called boundary conditions for the system. In many cases they can be more complex. For example:
 ;
;
 ,
,
Where  - given numbers. However, in order not to complicate the presentation, we will limit ourselves to the simplest form of additional conditions.
- given numbers. However, in order not to complicate the presentation, we will limit ourselves to the simplest form of additional conditions.
Taking advantage of the fact that the values  And
And  given, we rewrite the system in the form:
given, we rewrite the system in the form:

The matrix of this system has a tridiagonal structure:

This significantly simplifies the solution of the system thanks to a special method called the sweep method.
The method is based on the assumption that the unknown unknowns  And
And  connected by recurrence relation
connected by recurrence relation
 ,
, .
.
Here the quantities  ,
, , called running coefficients, are subject to determination based on the conditions of the problem, . In fact, such a procedure means replacing the direct definition of unknowns
, called running coefficients, are subject to determination based on the conditions of the problem, . In fact, such a procedure means replacing the direct definition of unknowns  the task of determining the running coefficients and then calculating the values based on them
the task of determining the running coefficients and then calculating the values based on them  .
.
To implement the described program, we express it using the relation  through
through  :
:
and substitute  And
And  , expressed through
, expressed through  , into the original equations. As a result we get:
, into the original equations. As a result we get:
 .
.
The last relations will certainly be satisfied and, moreover, regardless of the solution, if we require that when  there were equalities:
there were equalities:

From here follow the recurrence relations for the sweep coefficients:
 ,
, ,
, .
.
Left boundary condition  and ratio
and ratio  are consistent if we put
are consistent if we put
 .
.
Other values of the sweep coefficients  And
And  we find from, which completes the stage of calculating the running coefficients.
we find from, which completes the stage of calculating the running coefficients.
 .
.
From here you can find the remaining unknowns  in the process of backward sweeping using the recurrence formula.
in the process of backward sweeping using the recurrence formula.
The number of operations required to solve a general system by the Gaussian method increases with increasing  proportionally
proportionally  . The sweep method is reduced to two cycles: first, the sweep coefficients are calculated using formulas, then, using them, the components of the solution of the system are found using recurrent formulas
. The sweep method is reduced to two cycles: first, the sweep coefficients are calculated using formulas, then, using them, the components of the solution of the system are found using recurrent formulas  . This means that as the size of the system increases, the number of arithmetic operations will increase proportionally
. This means that as the size of the system increases, the number of arithmetic operations will increase proportionally  , but not
, but not  . Thus, the sweep method, within the scope of its possible application, is significantly more economical. To this should be added the special simplicity of its software implementation on a computer.
. Thus, the sweep method, within the scope of its possible application, is significantly more economical. To this should be added the special simplicity of its software implementation on a computer.
In many applied problems that lead to SLAEs with a tridiagonal matrix, its coefficients satisfy the inequalities:
 ,
,
which express the property of diagonal dominance. In particular, we will meet such systems in the third and fifth chapters.
According to the theorem of the previous section, a solution to such systems always exists and is unique. A statement is also true for them, which is important for the actual calculation of the solution using the sweep method.
Lemma
If for a system with a tridiagonal matrix the condition of diagonal dominance is satisfied, then the sweep coefficients satisfy the inequalities:
 .
.
We will carry out the proof by induction. According to  , i.e. when
, i.e. when  the statement of the lemma is true. Let us now assume that it is true for
the statement of the lemma is true. Let us now assume that it is true for  and consider
and consider  :
:
 .
.
So, induction from  To
To  is justified, which completes the proof of the lemma.
is justified, which completes the proof of the lemma.
Inequality for sweep coefficients  makes the run stable. Indeed, suppose that the solution component
makes the run stable. Indeed, suppose that the solution component  As a result of the rounding procedure, it was calculated with some error. Then when calculating the next component
As a result of the rounding procedure, it was calculated with some error. Then when calculating the next component  according to the recurrent formula, this error, thanks to the inequality, will not increase.
according to the recurrent formula, this error, thanks to the inequality, will not increase.
Definition.
Let us call a system a system with diagonal row dominance if the matrix elementssatisfy the inequalities:
 ,
,

Inequalities mean that in each row of the matrix  the diagonal element is highlighted: its modulus is greater than the sum of the moduli of all other elements of the same row.
the diagonal element is highlighted: its modulus is greater than the sum of the moduli of all other elements of the same row.
Theorem
A system with diagonal dominance is always solvable and, moreover, in a unique way.
Consider the corresponding homogeneous system:
 ,
,

Let's assume that it has a nontrivial solution 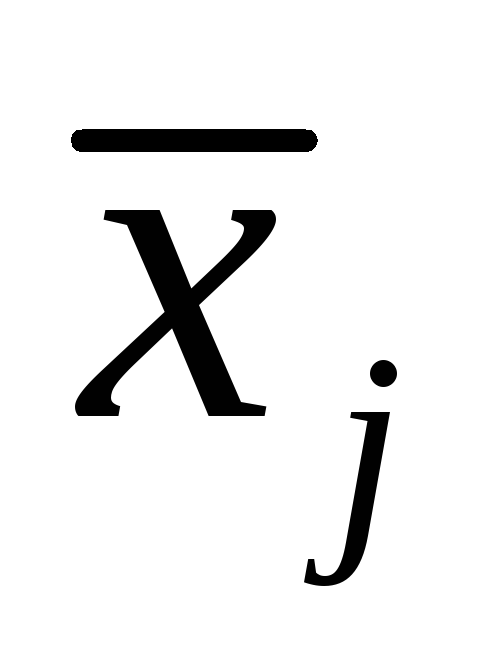 , Let the largest modulo component of this solution correspond to the index
, Let the largest modulo component of this solution correspond to the index  , i.e.
, i.e.
 ,
,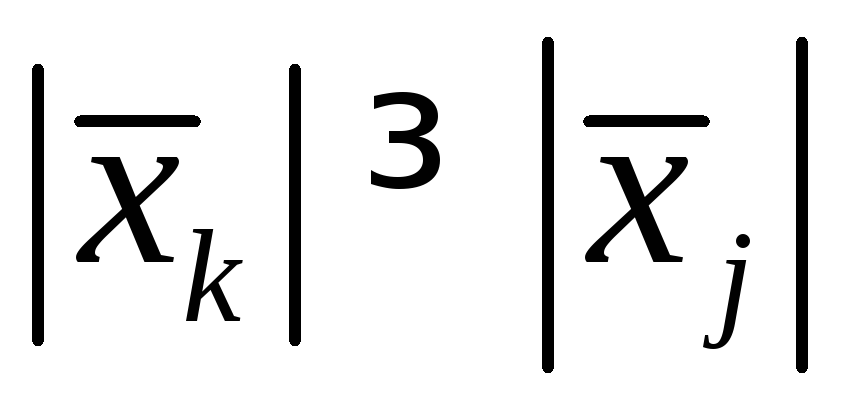 ,
,
 .
.
Let's write it down 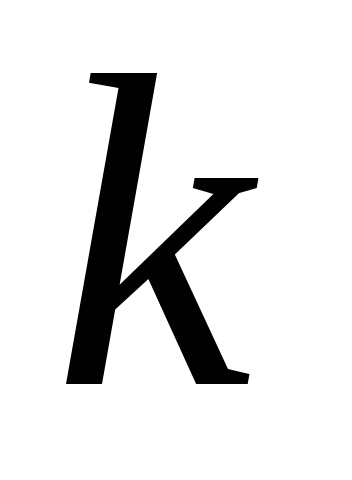 th equation of the system in the form
th equation of the system in the form

and take the modulus of both sides of this equality. As a result we get:
 .
.
Reducing inequality by a factor  , which, according to us, is not equal to zero, we come to a contradiction with the inequality expressing diagonal dominance. The resulting contradiction allows us to consistently make three statements:
, which, according to us, is not equal to zero, we come to a contradiction with the inequality expressing diagonal dominance. The resulting contradiction allows us to consistently make three statements:

The last of these means that the proof of the theorem is complete.
Systems with a tridiagonal matrix. Running method.
When solving many problems, one has to deal with systems of linear equations of the form:
, ,
,
 ,
, ,
,
where are the coefficients  , right sides
, right sides 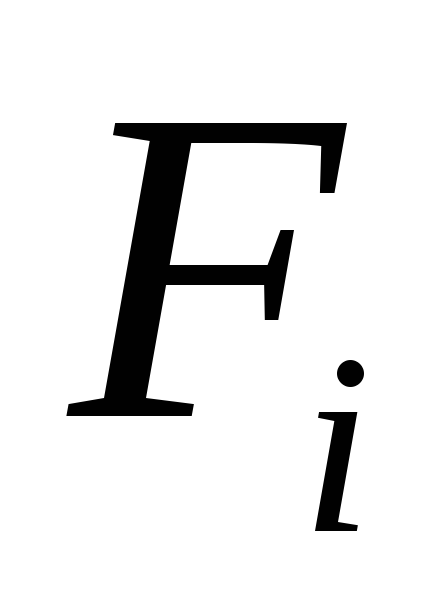
 known along with the numbers
known along with the numbers  And
And  . Additional relations are often called boundary conditions for the system. In many cases they can be more complex. For example:
. Additional relations are often called boundary conditions for the system. In many cases they can be more complex. For example:
 ;
;
 ,
,
Where  - given numbers. However, in order not to complicate the presentation, we will limit ourselves to the simplest form of additional conditions.
- given numbers. However, in order not to complicate the presentation, we will limit ourselves to the simplest form of additional conditions.
Taking advantage of the fact that the values  And
And 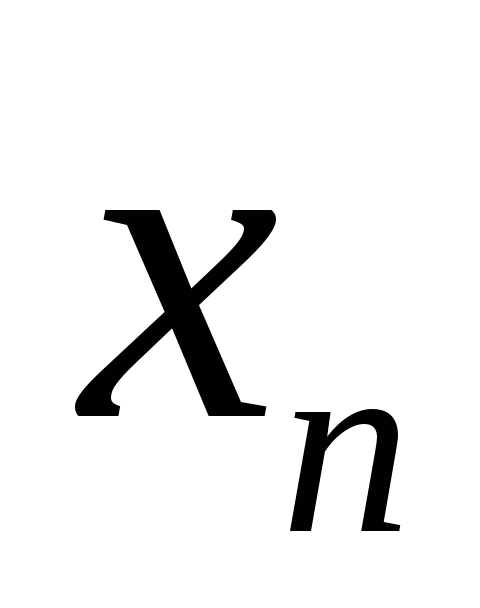 given, we rewrite the system in the form:
given, we rewrite the system in the form:

The matrix of this system has a tridiagonal structure:

This significantly simplifies the solution of the system thanks to a special method called the sweep method.
The method is based on the assumption that the unknown unknowns  And
And  connected by recurrence relation
connected by recurrence relation
 ,
, .
.
Here the quantities  ,
, , called running coefficients, are subject to determination based on the conditions of the problem, . In fact, such a procedure means replacing the direct definition of unknowns
, called running coefficients, are subject to determination based on the conditions of the problem, . In fact, such a procedure means replacing the direct definition of unknowns  the task of determining the running coefficients and then calculating the values based on them
the task of determining the running coefficients and then calculating the values based on them  .
.
To implement the described program, we express it using the relation 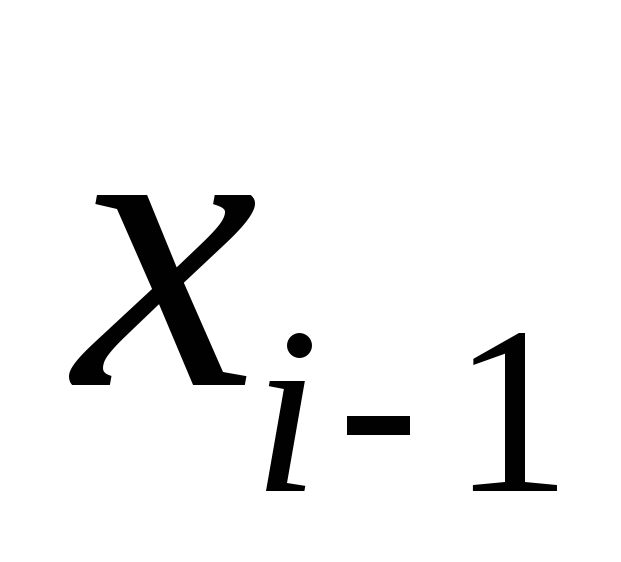 through
through  :
:
and substitute  And
And 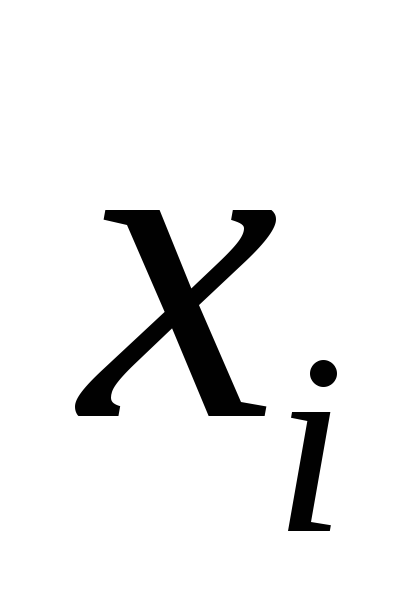 , expressed through
, expressed through 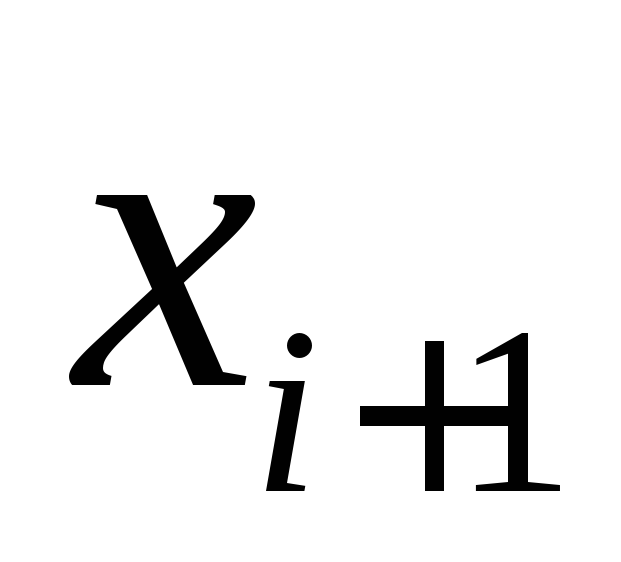 , into the original equations. As a result we get:
, into the original equations. As a result we get:
 .
.
The last relations will certainly be satisfied and, moreover, regardless of the solution, if we require that when  there were equalities:
there were equalities:

From here follow the recurrence relations for the sweep coefficients:
 ,
, ,
, .
.
Left boundary condition 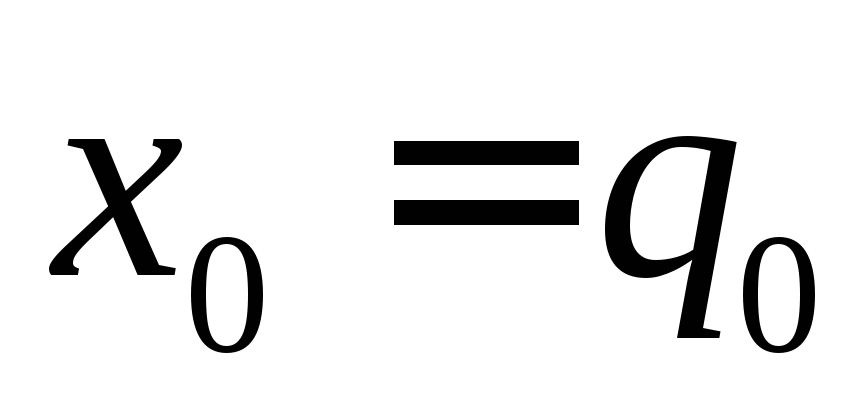 and ratio
and ratio  are consistent if we put
are consistent if we put
 .
.
Other values of the sweep coefficients  And
And  we find from, which completes the stage of calculating the running coefficients.
we find from, which completes the stage of calculating the running coefficients.
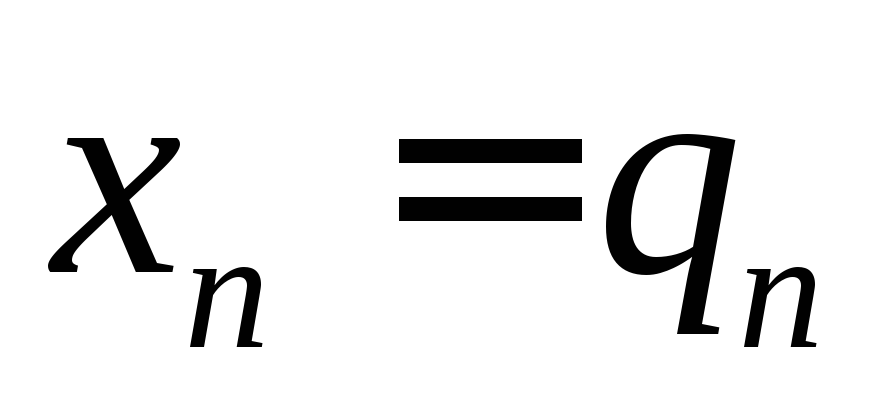 .
.
From here you can find the remaining unknowns  in the process of backward sweeping using the recurrence formula.
in the process of backward sweeping using the recurrence formula.
The number of operations required to solve a general system by the Gaussian method increases with increasing  proportionally
proportionally  . The sweep method is reduced to two cycles: first, the sweep coefficients are calculated using formulas, then, using them, the components of the solution of the system are found using recurrent formulas
. The sweep method is reduced to two cycles: first, the sweep coefficients are calculated using formulas, then, using them, the components of the solution of the system are found using recurrent formulas  . This means that as the size of the system increases, the number of arithmetic operations will increase proportionally
. This means that as the size of the system increases, the number of arithmetic operations will increase proportionally  , but not
, but not  . Thus, the sweep method, within the scope of its possible application, is significantly more economical. To this should be added the special simplicity of its software implementation on a computer.
. Thus, the sweep method, within the scope of its possible application, is significantly more economical. To this should be added the special simplicity of its software implementation on a computer.
In many applied problems that lead to SLAEs with a tridiagonal matrix, its coefficients satisfy the inequalities:
 ,
,
which express the property of diagonal dominance. In particular, we will meet such systems in the third and fifth chapters.
According to the theorem of the previous section, a solution to such systems always exists and is unique. A statement is also true for them, which is important for the actual calculation of the solution using the sweep method.
Lemma
If for a system with a tridiagonal matrix the condition of diagonal dominance is satisfied, then the sweep coefficients satisfy the inequalities:
 .
.
We will carry out the proof by induction. According to  , i.e. when
, i.e. when  the statement of the lemma is true. Let us now assume that it is true for
the statement of the lemma is true. Let us now assume that it is true for  and consider
and consider  :
:
 .
.
So, induction from  To
To  is justified, which completes the proof of the lemma.
is justified, which completes the proof of the lemma.
Inequality for sweep coefficients  makes the run stable. Indeed, suppose that the solution component
makes the run stable. Indeed, suppose that the solution component 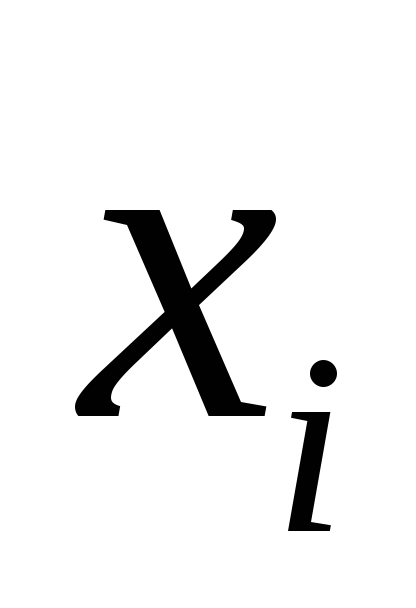 As a result of the rounding procedure, it was calculated with some error. Then when calculating the next component
As a result of the rounding procedure, it was calculated with some error. Then when calculating the next component  according to the recurrent formula, this error, thanks to the inequality, will not increase.
according to the recurrent formula, this error, thanks to the inequality, will not increase.
ST. PETERSBURG STATE UNIVERSITY
Faculty of Applied Mathematics – Control Processes
A. P. IVANOV
WORKSHOP ON NUMERICAL METHODS
SOLVING SYSTEMS OF LINEAR ALGEBRAIC EQUATIONS
Guidelines
Saint Petersburg
CHAPTER 1. SUPPORTING INFORMATION
The methodological manual provides a classification of methods for solving SLAEs and algorithms for their application. The methods are presented in a form that allows their use without recourse to other sources. It is assumed that the matrix of the system is non-singular, i.e. det A 6= 0.
§1. Norms of vectors and matrices
Recall that a linear space Ω of elements x is called normalized if a function k · kΩ is introduced in it, defined for all elements of the space Ω and satisfying the conditions:
1. kxk Ω ≥ 0, and kxkΩ = 0 x = 0Ω ;
2. kλxk Ω = |λ| · kxkΩ ;
3. kx + yk Ω ≤ kxkΩ + kykΩ .
We will agree in the future to denote vectors with small Latin letters, and we will consider them column vectors, with large Latin letters we will denote matrices, and with Greek letters we will denote scalar quantities (retaining the letters i, j, k, l, m, n for integers) .
The most commonly used vector norms include the following:
|xi |; |
|
1. kxk1 = |
|
2. kxk2 = u x2 ; t
3. kxk∞ = maxi |xi |.
Note that all norms in the space Rn are equivalent, i.e. any two norms kxki and kxkj are related by the relations:
αij kxkj ≤ kxki ≤ βij kxkj ,
k k ≤ k k ≤ ˜ k k
α˜ ij x i x j β ij x i,
and αij , βij , α˜ij , βij do not depend on x. Moreover, in a finite-dimensional space any two norms are equivalent.
The space of matrices with the naturally introduced operations of addition and multiplication by a number form a linear space in which the concept of norm can be introduced in many ways. However, most often the so-called subordinate norms are considered, i.e. norms associated with the norms of vectors by relations:
By marking the subordinate norms of matrices with the same indices as the corresponding norms of vectors, we can establish that
k k1 |
|aij|; kAk2 |
k∞ |
|||||||||||||
(AT A); |
|||||||||||||||
Here, λi (AT A) denotes the eigenvalue of the matrix AT A, where AT is the matrix transposed to A. In addition to the three main properties of the norm noted above, we note two more here:
kABk ≤ kAk kBk,
kAxk ≤ kAk kxk,
Moreover, in the last inequality the matrix norm is subordinated to the corresponding vector norm. We will agree to use in the future only the norms of matrices that are subordinate to the norms of vectors. Note that for such norms the following equality holds: if E is the identity matrix, then kEk = 1, .
§2. Diagonally dominant matrices
Definition 2.1. A matrix A with elements (aij )n i,j=1 is called a matrix with diagonal dominance (values δ) if the inequalities hold
|aii | − |aij | ≥ δ > 0, i = 1, n.
§3. Positive definite matrices
Definition 3.1. We will call a symmetric matrix A by
positive definite if the quadratic form xT Ax with this matrix takes only positive values for any vector x 6= 0.
The criterion for the positive definiteness of a matrix can be the positivity of its eigenvalues or the positivity of its principal minors.
§4. SLAE condition number
When solving any problem, as is known, there are three types of errors: fatal error, methodological error and rounding error. Let us consider the influence of the unavoidable error in the initial data on the solution of the SLAE, neglecting the rounding error and taking into account the absence of a methodological error.
matrix A is known exactly, and the right-hand side b contains an irremovable error δb.
Then for the relative error of the solution kδxk/kxk
It's not hard to get an estimate: |
|||||||
where ν(A) = kAkkA−1 k.
The number ν(A) is called the condition number of system (4.1) (or matrix A). It turns out that ν(A) ≥ 1 for any matrix A. Since the value of the condition number depends on the choice of the matrix norm, when choosing a specific norm we will index ν(A) accordingly: ν1 (A), ν2 (A) or ν ∞(A).
In the case of ν(A) 1, system (4.1) or matrix A is called ill-conditioned. In this case, as follows from the estimate

(4.2), the error in solving system (4.1) may turn out to be unacceptably large. The concept of acceptability or unacceptability of an error is determined by the statement of the problem.
For a matrix with diagonal dominance, it is easy to obtain an upper bound for its condition number. Occurs
Theorem 4.1. Let A be a matrix with diagonal dominance of value δ > 0. Then it is non-singular and ν∞ (A) ≤ kAk∞ /δ.
§5. An example of an ill-conditioned system.
Consider the SLAE (4.1) in which
−1 |
− 1 . . . |
−1 |
−1 |
|||||||||
−1 |
.. . |
|||||||||||
−1 |
||||||||||||
This system has a unique solution x = (0, 0, . . . , 0, 1)T. Let the right side of the system contain the error δb = (0, 0, . . . , 0, ε), ε > 0. Then
δxn = ε, δxn−1 = ε, δxn−2 = 2 ε, δxn−k = 2 k−1 ε, . . . , δx1 = 2 n−2 ε.
k∞ = |
2 n−2 ε, |
k∞ |
k∞ |
|||||||||||||
k k∞ |
||||||||||||||||
Hence,
ν∞ (A) ≥ kδxk ∞ : kδbk ∞ = 2n−2 . kxk ∞ kbk ∞
Since kAk∞ = n, then kA−1 k∞ ≥ n−1 2 n−2 , although det(A−1 ) = (det A)−1 = 1. Let, for example, n = 102. Then ν(A ) ≥ 2100 > 1030 . Moreover, even if ε = 10−15 we obtain kδxk∞ > 1015. And yet